Our JCDL 2025 paper with Bipasha Banerjee and Edward A. Fox examines how model disagreement changes retrieval evaluation when large language models filter scholarly records before ranking. “Learning from LLM Disagreement in Retrieval Evaluation” shows that disagreement between relevance labelers can identify cases near the boundary of an information need. In thematic retrieval tasks, particularly ones involving Sustainable Development Goals (SDGs), those boundary cases determine which records remain available to a dashboard, bibliography, or downstream synthesis.1
Universities and research organizations use bibliographic databases and digital library systems to describe how research contributes to strategic priorities. SDG mapping illustrates the retrieval problem. A university may want to know which publications support affordable clean energy, good health and well-being, or poverty reduction. Existing workflows often begin with Boolean search queries, including the SDG query sets used in Scopus and related bibliometric tools.
Boolean queries retrieve documents that contain the selected terms, but they do not determine whether a document makes a substantive contribution to the goal. A paper may mention “energy,” “poverty,” or “health” without advancing an SDG target. LLMs therefore enter these workflows as post-retrieval filters, reading abstracts and assigning semantic relevance labels after keyword retrieval has produced a candidate set.
Semantic relevance judgment is not a stable measuring instrument. In our study, two locally hosted open-weight models, LLaMA 3.1-8B and Qwen 2.5-7B, labeled the same abstract-SDG pairs as relevant or non-relevant using the same structured prompt. The models often agreed, but their disagreements occurred in the ambiguous middle, where the relation between a publication and an SDG was plausible but not obvious.
We built a corpus from Elsevier’s 2023 SDG-aligned Boolean queries, retrieved up to 20,000 Scopus records for each of the 17 SDGs, and cleaned the resulting metadata. The experiments focused on three goals that occupy different regions of the SDG co-occurrence structure. SDG 1 (No Poverty) clusters with social and governance goals, SDG 3 (Good Health and Well-Being) represents the health domain, and SDG 7 (Affordable and Clean Energy) anchors the technical and environmental cluster. After deduplication and cleaning, the working set for those three goals contained 46,755 labeled rows representing 46,573 unique abstracts.
Each model evaluated whether an abstract made a substantive contribution to the indicated SDG. We then isolated four kinds of cases: documents both models labeled relevant, documents both labeled non-relevant, documents only LLaMA labeled relevant, and documents only Qwen labeled relevant. This partition made disagreement the object of analysis rather than a residual error category.
The analysis measured agreement and Cohen’s kappa, compared lexical patterns in the disagreement subsets with TF-IDF and permutation tests, simulated ranked retrieval over the ambiguous cases, and trained logistic regression classifiers to test whether lexical features predicted which model assigned relevance.
Across the three SDGs, the models assigned the same label in 83.6% of cases, but Cohen’s kappa was only 0.467. Raw agreement overstated reliability because both models labeled many abstracts as relevant. Kappa showed weaker reliability once chance agreement and class imbalance were taken into account. The disagreement region, roughly 15-20% of decisions per SDG, was a structured set of borderline cases rather than a random residue.
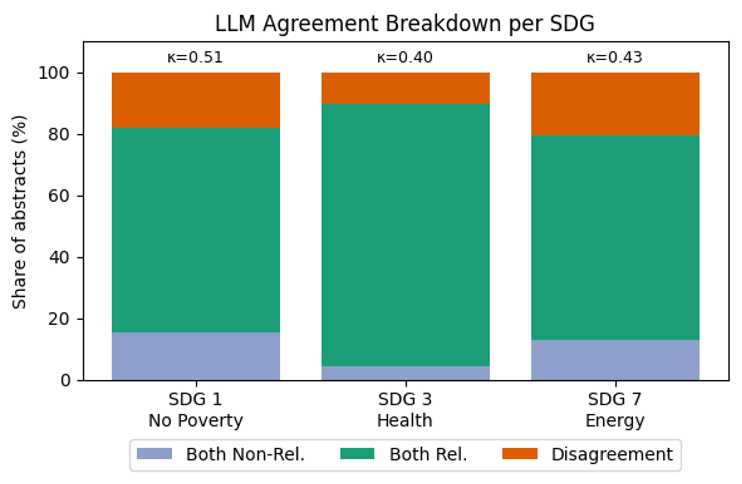
We ran a negative control to test whether the shared relevant labels reflected a general tendency to include documents. Applying the SDG 7 energy prompt to abstracts retrieved by the SDG 1 poverty query produced 91% agreement, with Cohen’s kappa of 0.59. The models jointly assigned non-relevance to 84% of cases, jointly assigned relevance to 7%, and disagreed on 8%. The main experiment therefore cannot be reduced to affirmative-label bias; the models converged on rejection when the prompt and candidate set described conceptually distant SDGs.
Lexical analysis identified model-specific relevance criteria. For SDG 1, LLaMA assigned relevance more often to documents using healthcare access terms such as health, care, insurance, and coverage, while Qwen assigned relevance more often to documents using terms associated with structural inequality, wealth, income, and taxation. For SDG 3, LLaMA assigned relevance more often to clinical and procedural terms, while Qwen assigned relevance more often to molecular and cellular terms. For SDG 7, LLaMA assigned relevance more often to systems and infrastructure terms, while Qwen assigned relevance more often to electrochemistry and battery terms. The FDR-adjusted p-values for the reported terms were below 0.001.
| SDG | LLaMA-relevant terms | Qwen-relevant terms |
|---|---|---|
| SDG 1 No Poverty |
health (+0.019), care (+0.014), insurance (+0.013), covid (+0.010), coverage (+0.010) | inequality (-0.020), wealth (-0.012), income (-0.009), tax (-0.008), political (-0.005) |
| SDG 3 Health |
patients (+0.023), risk (+0.007), tavr (+0.007), stroke (+0.006), coronary (+0.006) | cells (-0.019), cancer (-0.018), cell (-0.017), tumor (-0.015), human (-0.007) |
| SDG 7 Energy |
fuel (+0.006), computing (+0.006), neural (+0.004), plasma (+0.004), network (+0.005) | lithium (-0.018), capacity (-0.018), ion (-0.016), batteries (-0.016), anode (-0.015) |
The retrieval experiments show a direct consequence for ranked output. Under a fixed scoring function applied to the same disagreement pool, the top-ranked documents changed according to the model that filtered the candidate set. In SDG 7, the LLaMA-relevant subset contained 19 of the top 20 centroid-ranked disagreement documents, while the Qwen-relevant subset contained one. The ranking logic was held constant, so the difference came from the earlier relevance filter.
A separate classification experiment showed that disagreement was learnable from lexical features. Logistic regression classifiers trained on TF-IDF features predicted which model labeled a disagreement document as relevant with AUC scores above chance for all three goals. The AUC was 0.739 for SDG 1, 0.753 for SDG 3, and 0.703 for SDG 7. These results do not identify either model as correct. They show that the models used different, learnable lexical criteria when assigning relevance.
The paper does not use LLM labels as ground truth. For subjective retrieval tasks, including policy-relevant tasks such as SDG assessment, a single definitive label may not exist. A publication can contribute to a goal directly, indirectly, methodologically, or under a particular interpretation of the target. In that setting, the better evaluation question is how each model changes the corpus available for ranking and synthesis.
A single LLM filter cannot be described as neutral preprocessing in SDG retrieval. It determines document eligibility before ranking begins and can remove alternative interpretations of relevance from the result set. A dashboard, literature review, or retrieval-augmented generation workflow built on a filtered corpus inherits those exclusions.
Digital library systems that use LLM filtering should report and inspect disagreement sets rather than relying on aggregate agreement. Audits should identify which topics each model admits or excludes, which disciplines gain or lose representation, which lexical cues mark the edge of relevance, and which documents disappear before ranking begins.
Retrieval workflows should expose model disagreement before downstream synthesis. Multi-model filtering, human review of disagreement cases, and audits of model justifications can locate where model-specific criteria enter the retrieval process. Extending the analysis to additional models, domains, and RAG-based policy briefs would measure how filtering variability changes the substantive content of generated outputs.
When LLMs disagree in thematic retrieval, the disagreement identifies the documents most sensitive to the definition of relevance. Those documents require analysis before the filtered corpus is used for institutional reporting or evidence synthesis.
The paper is available through IEEE with DOI 10.1109/JCDL67857.2025.00024, and the project code is available on GitHub.
-
William A. Ingram, Bipasha Banerjee, and Edward A. Fox. 2025. Learning from LLM Disagreement in Retrieval Evaluation. In 2025 ACM/IEEE Joint Conference on Digital Libraries (JCDL). IEEE. https://doi.org/10.1109/JCDL67857.2025.00024 ↩